Private, GPU-Accelerated AI Infrastructure
for Real-World Systems.
Rootstar builds local-first AI systems designed for continuous operation, low-latency inference, and full data control — powered by NVIDIA-class hardware.
From persistent agent runtimes to voice-driven environments, our systems are built to operate where reliability, privacy, and control matter most.
Built for Persistent, Always-On AI Workloads.
Rootstar systems are designed for continuous AI operation — requiring local inference, hardware-level optimization, and real-world deployment reliability. Not batch processing. Not API wrappers. Infrastructure that runs.
Inside Obsidian Grid
Four modules running on local GPU hardware. Velithra Core handles inference; OpenClaw runs orchestration; Aegis provides system control. Nyx Interface is an optional control surface — the pipeline operates without it.
- vLLM inference with continuous batching
- FastAPI bridge + Nginx gateway
- NAS-backed model storage
- Multi-client session isolation
- Sustained multi-client GPU inference workloads
- Multi-step task orchestration
- REST + webhook integrations
- Policy-guarded execution
- Agent-driven workflow chains
- GPU + inference health monitoring
- Automated alerting + reporting
- Anomaly detection
- Decision support analytics
- Persona-enforced avatar assistant
- Voice interface (planned)
- Dashboard control surface
- Fully optional — infrastructure runs independently
System flow
Linear pipeline from hardware to operator output. Nyx Interface sits alongside — not in the critical path.
What this is
- GPU-accelerated local inference infrastructure
- Persistent agent runtime with memory and orchestration
- Real-world deployment on NVIDIA hardware
- Systems built for continuous, always-on operation
- A generic chatbot or API wrapper
- A cloud-only or batch-processing system
- A one-off consulting engagement
- A demo without deployment path
What Rootstar Delivers
Deployable systems — not concepts. Each component is production-ready or actively in build with measurable completion criteria.
GPU-accelerated inference running on NVIDIA hardware. vLLM with continuous batching, FastAPI bridge, and NAS-backed model storage. No cloud dependency for core workloads.
Agent execution layer with memory, task orchestration, and environment awareness. Designed for always-on operation — not single-turn request handling.
Validated deployment patterns for home, edge, and hub configurations. Hardware-specific tuning included. Tested against Luma CareOS and simulation workloads.
System-level visibility across GPU utilization, inference throughput, and workflow state. Automated alerting, anomaly detection, and lifecycle management.
Qualified deployment partners and pilot users gain access to working system builds before general availability. Limited onboarding now open.
Next 90 days
Focused on deploying real-world, continuous-use AI systems across controlled environments. Four milestones — each with a measurable completion criterion.
Velithra Desktop
Local Operator Console for Obsidian Grid
Velithra Desktop is the control surface for private AI infrastructure. It gives operators a single interface to monitor nodes, route tasks, manage memory workflows, and enforce safety policies across a local-first deployment.
Live status for inference nodes, memory services, and automation workers.
Launch and route predefined workflows across available compute lanes.
Search and inspect persistent context, recent actions, and retrieval traces.
Unified event and error stream with retry/escalation controls.
Policy modes, execution guardrails, and emergency stop controls.
Proof of Capability
These programs demonstrate how our infrastructure performs in live, multi-variable environments across simulation, decision support, and operator workflows.
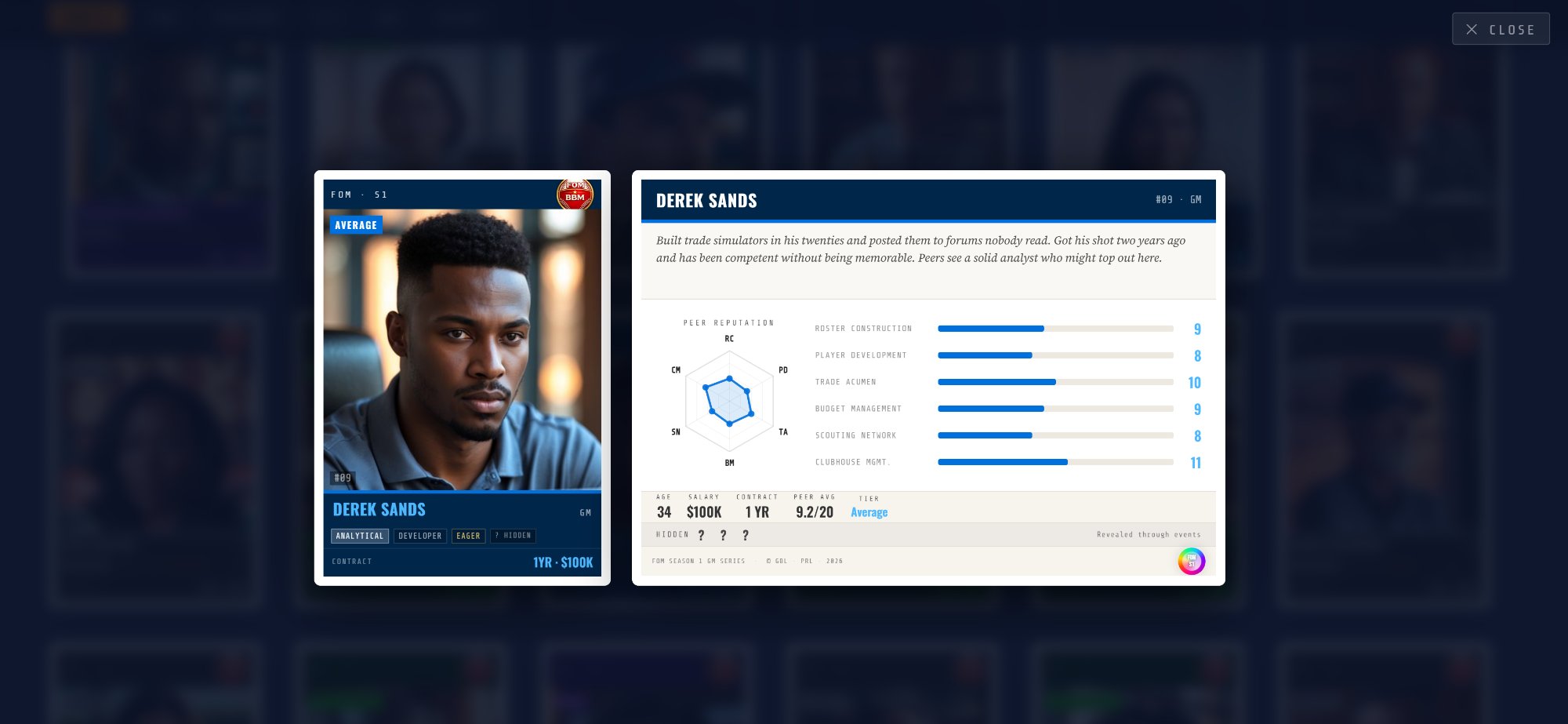
Applied decision-system prototype for sports operations, including trait engines, budget mechanics, briefing workflows, and event-driven management logic. Designed to test orchestration reliability and human-in-the-loop control under dynamic conditions.

Narrative simulation environment used to test autonomous agent interaction, world-state orchestration, and control-surface behavior in high-context scenarios.
Luma CareOS — A Real-World Deployment
Built on persistent local inference systems, Luma operates as a continuous AI workload rather than a request-response tool.
Luma CareOS is a continuous, voice-driven AI system built on Rootstar infrastructure, designed for real-world behavioral guidance and caregiver support. It operates as a persistent companion layer, delivering daily guidance, reminders, and interaction through local AI systems.
Designed to feel calm, supportive, and non-intrusive in daily use.
- Persistent local AI runtime
- Voice-driven interaction layer
- Human override and escalation controls
- Privacy-first deployment options
Scheduled, low-friction check-in prompts with status logging. Flags missed responses for caregiver review without surveillance overhead.
Configurable reminder schedules for medications, appointments, and recurring tasks. Delivered locally — no cloud dependency required.
Routes status updates and exception alerts to designated family contacts. Configurable escalation paths with optional acknowledgment tracking.
Persistent local journal for personal notes, preferences, and daily context. Enables AI-assisted recall without sending private data to external services.
Luma Deployment Ladder
Three deployment tiers, sequenced for access, reliability, and household fit. Each tier is production-capable — not a prerequisite for the next.
Voice channels, caregiver portal, and centralized AI services for rapid household adoption. No local hardware required. Operational from day one.
- Cloud-assisted AI inference
- Caregiver coordination portal
- Voice channel integration
- Software-first onboarding
Optional local node for privacy-first households and resilient home operations. Runs core Luma workflows on-premise — no cloud dependency for primary functions.
- Local inference node
- Offline-capable primary workflows
- Privacy-first data handling
- Obsidian Grid edge deployment
Regional GPU hubs for high-concurrency care operations, richer models, and broader household coverage. NVIDIA GB-class hardware at the infrastructure layer.
Designed for high-density, continuous inference workloads across multiple households.
- NVIDIA GB-class GPU infrastructure
- High-concurrency multi-household serving
- Richer contextual model capabilities
- Regional redundancy and coverage
Who's building this
Systems architecture, local AI infrastructure, and automation orchestration. Builds the technical platform powering Luma CareOS through Obsidian Grid.
Lifelong elder-care professional with nursing assistant and phlebotomy background. Leads care workflow design for Luma CareOS, including daily check-ins, medication continuity, family coordination, and dignity-first support practices grounded in real-world caregiving.
Apply for Early Access
We are onboarding a limited number of early deployments and pilot users. Two paths are open now.
Pilot households start software-first; edge and Spark-enabled tiers follow deployment fit.